


While other version control systems might focus on storing changes or diffs, Git primarily stores the state of the entire directory and its files as snapshots in a commit. Git's snapshot model ensures every commit is a complete, standalone entity - each commit represents the entire state of your files at that moment. This approach makes operations like checking out previous states or merging much more straightforward and efficient. Storing complete snapshots of every version might seem much less space-efficient than storing incremental changes. However, Git employs several sophisticated compression and optimization techniques to minimize storage and performance costs.
Objects and references
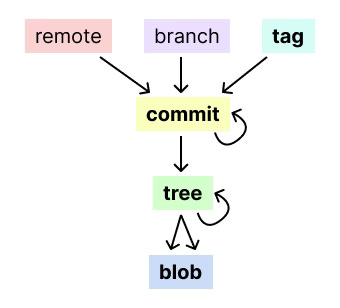
Git handles four types of objects: commits, trees, blobs, and tags. These objects are immutable, meaning they cannot be altered once they are created. Each object is identified by a 40-character SHA hash - a simple way of creating globally unique identifiers in a distributed manner. In .git/objects/, objects are saved under a directory named according to the first two characters of the SHA, with the filename being the remaining 38.
Commits contain metadata (author and commit message) and pointers to tree objects. They represent the entire state of the repository at a given time, acting as a snapshot of your project.
Before creating a commit, files must be "staged" using
git add. The "staging area" is where a new snapshot is built up over time. Then, once you commit, that snapshot is persisted to your repository.
Trees represent the structure of your project at a given time. They contain pointers to blob objects (your files) and other tree objects (directories).
Blobs (stands for "binary large object") hold the file data but don't contain any metadata about the file itself.
Tags are references to specific commit objects, often used to mark release points like v1.0, etc.
Both tags and branches are pointers to commits with metainformation and do not represent copies of the project. Branches and remotes are examples of references. Unlike objects, references are mutable. They represent moveable pointers to a commit and are stored in .git/refs/. When you create a new branch, Git creates a new file in .git/refs/, which points to the latest commit hash on that branch.
Diffs?
When most other version control systems, for example, Subversion, store a new version of a project, they do, in fact, persist a diff corresponding to the changes made from the previous version. However, when you make a commit using Git, it creates and stores a whole new tree object. This tree object will point to a series of blobs and other trees and can be directly re-expanded into a copy of the working directory at that time. If some files have not been modified since the last version, the new tree may point to previously created blobs (blobs and subtrees may be shared between different trees - identical files and directories are only stored once and have a unique hashed filename). However, if you even change one character in a file, a new blob is created corresponding to that file, with a new unique SHA identifier.
When a user requests to view the differences between two project versions, Git dynamically calculates the diff at that moment. It does this by comparing the two associated snapshot trees, identifying files that differ, and then computing the specific lines that have changed within those files. This process involves a diff algorithm, typically Myers' diff algorithm, which finds the shortest sequence of additions and deletions that transforms one file into another. Note that these diffs are not stored in the repository but are generated on demand.
Compression
Git's compression layer makes the additional memory cost very low. If you have many blobs with similar contents, Git is smart enough to take all those blobs together and run a compression algorithm. This is why a project can have its entire Git history use less memory than one checked-out repository version.
This compression layer works via a mechanism known as "packfiles". Git stores objects individually when they are initially created - this is called a "loose" object format. However, as the repository grows, Git periodically packs several of these objects into a binary file called a packfile. Alongside the packfile, a packfile index is created, which specifies offsets for each object in the packfile.
To figure out which objects to pack together in a single packfile, Git uses a heuristic that involves the object's type, size, and history. These are likely to be different versions of the same source file and differ by a smaller amount than randomly sampled files.
Within a packfile, Git uses delta compression. Instead of storing the complete content of each object version, Git stores the first version of the binary object fully, then only instructions on what differences to apply to reconstruct the other versions. This dramatically reduces storage size for very similar or slightly changed files. More details on the packfile delta format can be found here.
After delta compression, Git further compresses the packfile using zlib, a general-purpose compression library that combines Lempel-Ziv and Huffman coding. This step further reduces the file size, ensuring the packfile is as compact as possible. (More recent Git versions use zstd instead of zlib, a newer library developed by Facebook that provides better compression ratios and speeds.)
Git also periodically repacks objects to optimize their storage. During this process, it may adjust which objects are packed together based on the current state of the repository, including which files are often accessed together or have been modified similarly.
Git's garbage collection mechanism also optimizes repository efficiency by periodically identifying and removing unreachable objects, such as old commits and blobs, thus reclaiming space and maintaining performance.
