Linear representations in transformers
much probing
Techniques like activation steering and linear probing work on transformers because they represent many important concepts and variables linearly. Despite extensive research over the past year showing the diversity of linearly represented concepts, there’s still a lot left to understand about how these linear representations emerge and what the most effective techniques to interpret and modulate them are.
Here is a (non-exhaustive) selection of papers on linearity in transformer representations:
Subramani et al. 2022: Extracting Latent Steering Vectors from Pretrained Language Models
Li et al. 2023: Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
Tigges et al. 2023: Linear Representations of Sentiment in Large Language Models
Park et al. 2023: The Linear Representation Hypothesis and the Geometry of Large Language Models
Hendel et al. 2023: In-Context Learning Creates Task Vectors
Rimsky et al. 2023: Steering Llama 2 via Contrastive Activation Addition
The general types of points made in these papers are that
High-level behavioral concepts are linearly represented in the latent space (often found by examining the residual stream)
e.g. sentiment, behavioral tendencies (corrigibility, power-seeking tendency), refusal
Internal “state” variables are linearly represented in the latent space
e.g. the position of chess pieces on a board
Latent variables that are induced by the semantic content of the preceding context can be extracted from the residual stream and in many cases used to replace the context tokens
e.g. instead of describing a task, you derive a task vector from the internal representations of context describing that task, and then just steer with the task vector to elicit the task-related behavior
You can intervene with a linear perturbation to the model’s activation spaces to modulate the amount of some behavior
e.g. increasing truthfulness via a linear inference-time intervention at multiple attention heads across the model
Here are some questions that would be interesting to investigate further:
What does the linearity of features in activation spaces tell us about the correct model of computation in transformers?
At the depth where a latent variable can be read off from the activations with a linear function, it’s easily accessible for model components, such as attention heads, to use for further computation. Therefore, we can see the nonlinear components/MLPs in transformers as responsible for making complex functions of the input linearly representable, and thereby “simple to read off”.
Boolean-circuit-based models of computation must account for this observed linear structure rather than assuming feature directions are either present or not in a binary fashion.
Can we use linear probing and steering techniques as robust handles on models’ intermediate states of computation, e.g. to elicit latent knowledge or detect unwanted kinds of reasoning?
If transformers make important latent variables linearly readable, this is good news for us as it makes the task of inspecting and altering the intermediate state simpler.
Which model components generate/write to linear feature directions?
It looks like residual-stream directions corresponding to high-level features are relatively constant across layers
Analyzing which model components are responsible for generating these directions could be used as a method of circuit discovery
What types of features end up linearly represented?
A variable being readable with a linear probe doesn’t guarantee that the linear direction is actually used in future computation - additional interpretability experiments or causal interventions (e.g. testing the effect of steering) are needed to validate this
How do different types of finetuning affect internal feature representations?
To what extent are linear feature directions found via functions of existing representations similar to those found via optimization?
We can contrast the representations of “good” and “bad” to find a “goodness” vector, using standard techniques, and many experiments have shown that we can use such a vector to modulate the sentiment of the output
We can also finetune a bias for the residual stream that results in the same change in sentiment
How similar are these directions (for a range of representation types)?
What’s going on with the linear representations at middle layers?
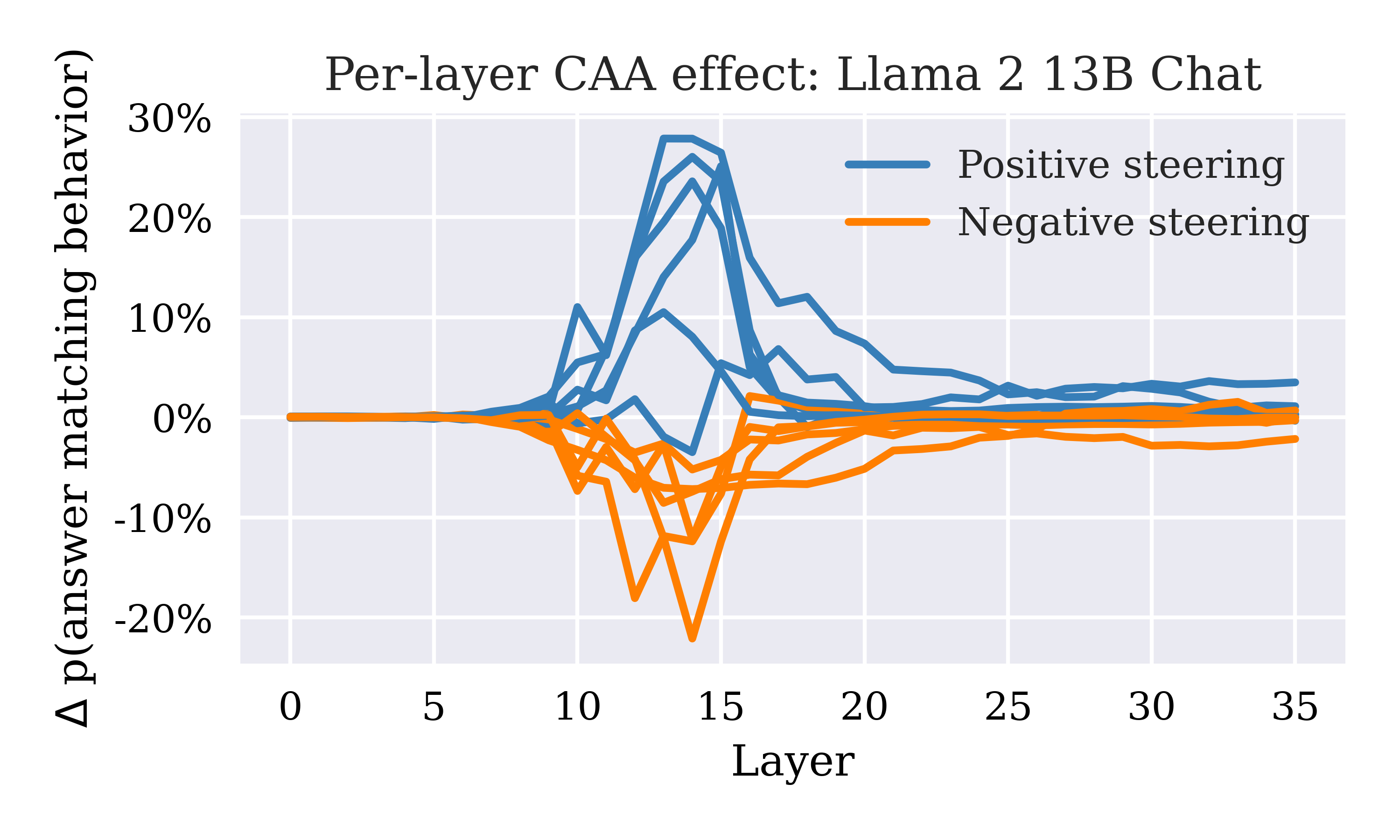
In many activation steering experiments, steering vectors derived from a small set of intermediate layers are significantly more effective than those derived from any earlier or later layers.

Cosine similarity of CAA steering vectors derived from different layers of Llama 2 7B and 13B Chat models. There is a clear transition point around a third of the way through the transformer layers. 
Efficacy of CAA at different layers of Llama 2 13B Chat (separate lines corresponding to steering different behaviors).