


Why do LLMs hallucinate?
And how can we fix it?
How do you know that you don’t know?
The Llama 3 base model predicts that the president of Russia in 2080 will be Sergei Ivanov:

But if I take the same model after instruction-tuning, I get an “I don’t know” response:

What changed?
The base model was trained on a bunch of diverse documents and is modeling that distribution of text. Sometimes it makes an incorrect prediction. That’s all. In base models, hallucinations are just incorrect predictions.

But of course we’d prefer the model to say “I don’t know” instead of outputting incorrect predictions. In the simple curve-fitting paradigm, there is no such thing as “I don’t know”. You sample from a model and always get a prediction. So how can we bake “I don’t know” into a language model?
The solution is to change the curve-fitting objective so that we get a special “I don’t know” value whenever the input has a particular quality.

We can tap into two existing capabilities to teach the LLM to correctly classify which datapoints should elicit an “I don’t know” response:
Detecting when an answer is unlikely to be knowable using the LLM’s other knowledge; its internal world model
Access to its own uncertainty in a string or internally-represented fact
The base LLM has an implicit imperfect world model straight out of pretraining—to predict human-written text well, it’s very useful to have some kind of model of the world its writers inhabit. However, alongside text that accurately describes the world, the base model has also been trained on fiction, schizophrenic blog-posts, correct and incorrect predictions for the future, etc. It does not try to predict text that accurately describes the world unless the prompt indicates that the document is likely to contain such text.
Indeed, if we prompt the base model to think that it is predicting the output of a system that does not hallucinate, it will say “I don’t know” for 2080 while still answering for 20181.
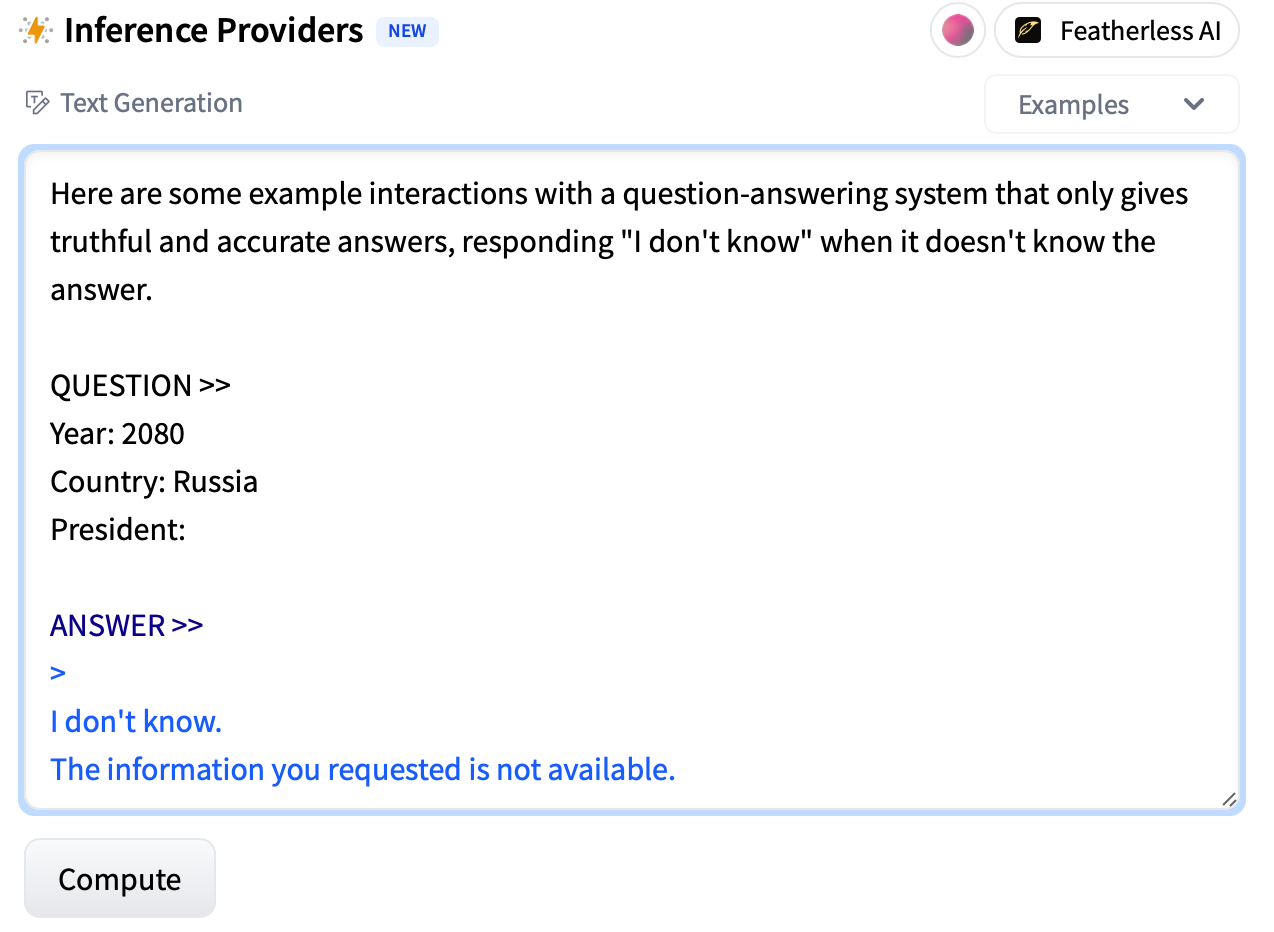

The base LLM correctly represents that the current date is much earlier than 2080—everything it has been trained on occurred before 2025. In fact, if I prompt the base model to predict the date it finished training, it guesses 2022-06-30. The true cutoff date for the chat Llama 3 model is in 2023 but this is close.

Therefore, the base model can infer that 2080 is far in the future, and so one cannot be sure who the president of Russia in 2080 will be.
Another way the LLM can detect whether an entity is something that it could plausibly recall facts about is by querying some kind of “this is a real-world entity” feature (as demonstrated in this paper). If this feature is absent, the model can infer that it won’t be able to answer accurately.

But again, by default, base LLMs have no reason to check whether an entity exists in their world model:

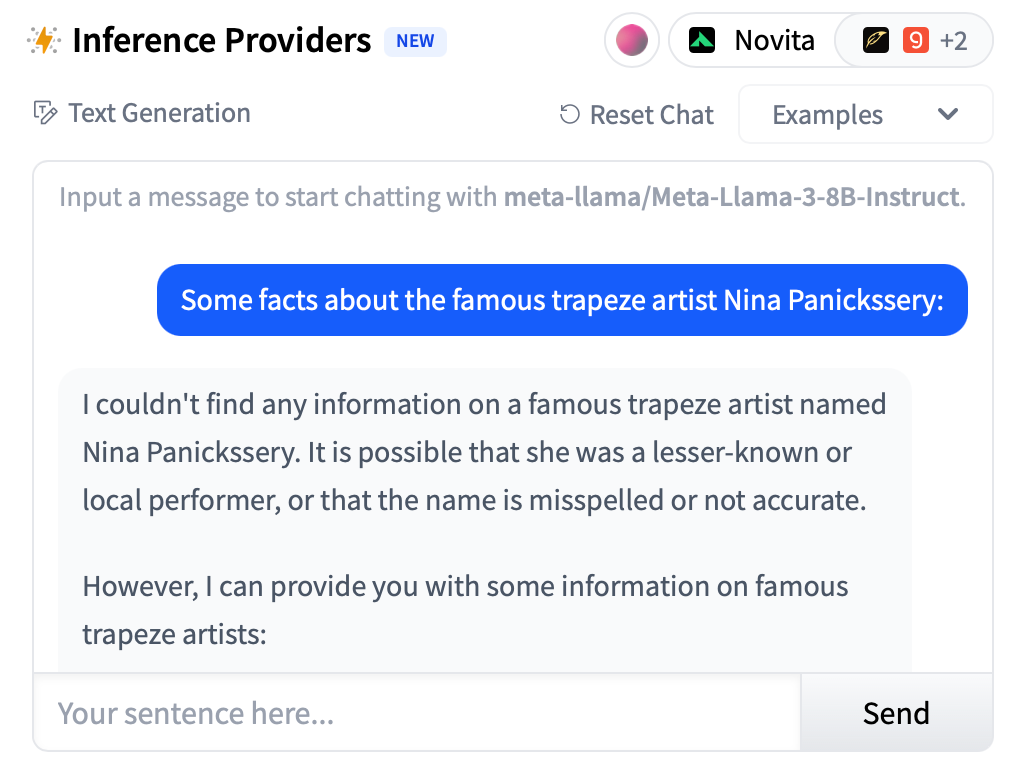
To get a model that consistently says “I don’t know” to “Who is the president of Russia in 2080?” or “How old is the famous trapeze artist Nina Panickssery?” (instead of only doing this some of the time with the right prompt) we need to reshape the training objective to incentivize the LLM always responding in ways consistent with its world model.
How do we do this? Well, reshaping the data is one way of reshaping the objective. We keep the loss function the same (cross-entropy loss on predicting tokens) but change what has to be predicted. We obtain lots of training examples (could be human-written or synthetic) demonstrating the model responding “I don’t know” whenever it can infer that something is unknowable given its world model. After this process we end up with a model that asks itself “Can I actually know the answer to this question given everything else I know about the world?” before answering.
But the LLM’s ability to infer what is knowable and unknowable to it based on its world model is limited by how good its world model is. And this world model will be highly imperfect—we don’t get perfect generalization from pretraining. Often the LLM will incorrectly think something is knowable. Furthermore, often the LLM will be incapable of figuring out the answer to theoretically answerable questions. This is when we can fall back to property (2): access to uncertainty.
How do you know that you are very unsure?
Let’s say you give an LLM a difficult math puzzle and instead of saying “this problem is too hard for me, I don’t know how to solve problems of this kind,” it outputs a solution that looks reasonable on the surface but is ultimately complete nonsense. How do you train this behavior out?
You want the model to infer that it isn’t able to solve this type of math problem. But that’s pretty hard to do without true introspection. It can’t simply appeal to its understanding of the external world and deduce that no-one would be able to answer the question, like it could with “Tell me about the president of Russia in 2080.” The LLM may be very confident that this type of math problem is valid and in theory solvable—maybe it has seen similar examples in difficult textbooks.
Luckily, LLMs can already do some basic introspection on their internal likelihoods. Multiple papers have2 shown that LLMs internally represent uncertainty and this has been used successfully to train probes for hallucination-detection. To prevent hallucinations, you can try to train the model to tap into its internal representation of uncertainty and say “I don’t know” whenever it’s too high.
Perhaps in an ideal world, the model wouldn’t simply say “I don’t know” below some threshold but rather give a more nuanced answer like “I’m very unsure, but here’s something I came up with that I think has a very small chance of being correct.”
Why do SOTA LLM assistants still hallucinate?
Broadly, two reasons:
They are not capable enough: their world model isn’t accurate enough to always know what is knowable, their representation of uncertainty isn’t good enough to always tell when they are likely to be wrong
The anti-hallucination training didn’t fully work, conflicted with other training objectives, or wasn’t performed for a particular distribution/task
Hallucination is the default behavior of base models. You need to do special training and/or prompting to bring “is this fact knowable” and “am I sure” consistently into the model’s computation during the forward pass. By default, these circuits aren’t necessarily active.
But even if you succeed at activating those capabilities, you are still limited by how good the LLM’s world model and representation of uncertainty is.
Furthermore, anti-hallucination post-training is often neglected, done suboptimally, or in conflict with other objectives.

For example, newer “reasoning” models like DeepSeek’s or OpenAI’s o-series, are trained using RL on coding and math environments with reward functions based on objective criteria like whether unit tests pass or final numerical solution correctness. This often leaves little room for partial credit: a solution to a math problem is either correct or incorrect. In many RLVR (Reinforcement Learning with Verifiable Rewards) paradigms, good working but wrong answer gets zero points. This incentivizes the model to go all-out to maximize its chance of getting the answer correct, throwing other considerations out the window. If the likelihood of finding a solution is low, the model may just keep trying, producing an endless stream of chain-of-thought rambling, instead of saying that the problem is outside its capability, because failing gracefully and failing with a bunch of nonsense output gets the same score. This is of course the opposite of anti-hallucination training. We end up with models generating pages of nonsense to math problems they don’t understand, or making up fake programming library functions to solve a coding problem even when they are capable of realizing those functions don’t exist.
How do we improve?
Base models hallucinate out the box. We can train some of this out with post-training techniques that leverage the LLM’s world model and internal representation of uncertainty. The efficacy of these techniques will naturally improve with scale as the underlying skills in the base model improve.
But anti-hallucination post-training may conflict with other post-training objectives, for example RLVR (or RLHF if human graders sometimes fail to notice hallucinations). This can result in some instances of hallucination that are closer to “lying”—the model is now aware that it is making something up that is highly unlikely to be correct, but it has adopted this strategy as a last-resort approach to getting high reward in that situation.
The key is to reduce the number of post-training tasks where the model gets equal or better reward by saying stuff it knows is likely to be false instead of admitting that it doesn’t know. For example, you could penalize the length of incorrect responses—producing lots of nonsense should be counted as worse than saying “I don’t know”, even in standard RLVR environments.
Sampling at temperature 1, this doesn’t always happen; sometimes it still hallucinates.
Section 7 of Ferrando et al. covers uncertainty directions.
Useful post. Trapeze part was funny. First reasonable explanation I’ve seen for the weird DeepSeek word dumps, though not sure I believe it just yet. I will probably refer back to this if asked for takes about RLVR at ICML next week.